Bigdata
1. Hadoop
1.hdfs集群:负责文件读写
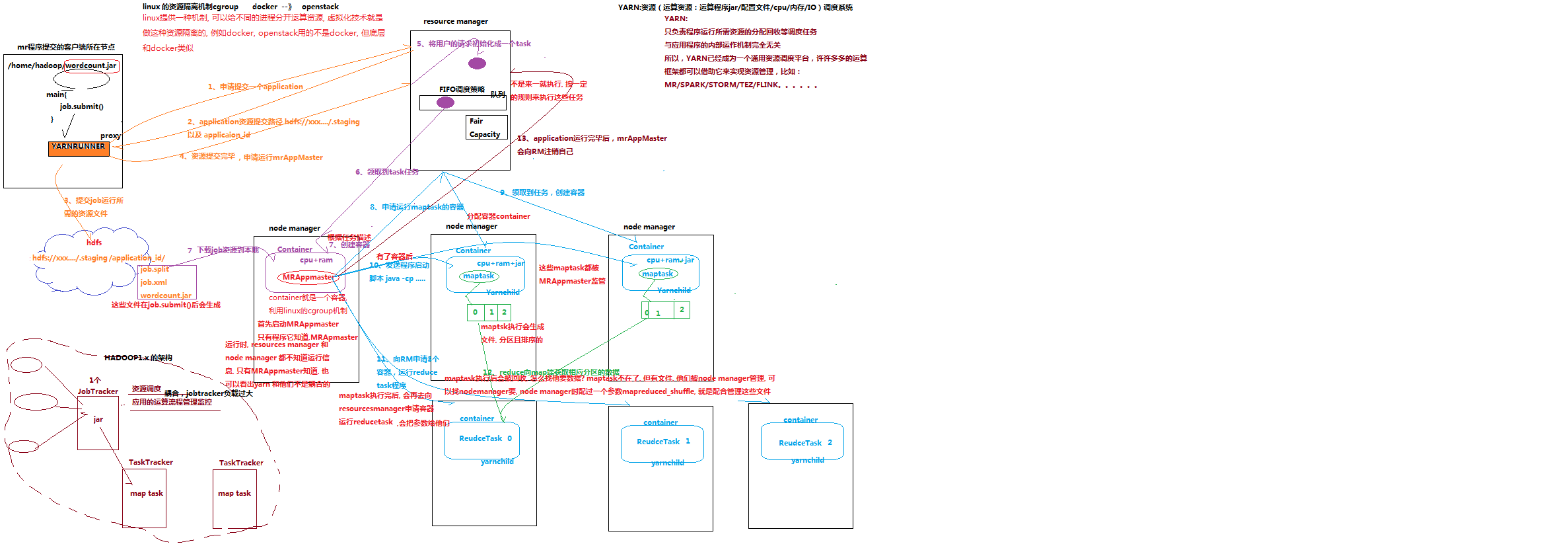
2.yarn集群:负责为mapredece程序分配运算硬件资源
Hadoop配置:
1.core-site.xml:fs.DefaultFS hadoop.tmp.dir
2.hadoop.env.sh: JAVA_HOME
3.mapred-site.xml: mapreduce.framework.name
4.hdfs-site.xml: dfs.replication
5.yarn-site.xml: yarn.resourcemanager.hostname yarn.nodemanager.aux-services
slaves:自动化脚本使用的配置文件
修改Linux启动等待时间 vi /etc/fstab
mkdir -p /aa/bb/cc 可以直接建立aa下的bb下的cc 创建层级文件
挂载光驱:mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom
设置光驱开机挂载:vi /etc/fstab 增加 /dev/cdrom /mnt/cdrom iso9660 defaults 0 0
rename 文件重命名
与mv的区别
mv 支持单个文件重命名
rename 支持多个文件重命名
cp /aa/* /bb 复制aa下的所有文件到bb下面
hadoop fs -put filename / 上传文件
hadoop fs -get filename 下载文件
hadoop 副本数由客户端决定(conf.set 》自定义配置文件》jar包中的配置)
namenode和datanode两个的工作目录不能在同一个文件夹下,否则会启动不起来。
eclipse 本地运行代码时遇到调用远程路径权限不够时,在eclipse客户端运行配置时添加VM arguments参数使用hadoop用户运行,参数为“ -DHADOOP_USER_NAME=hadoop ”
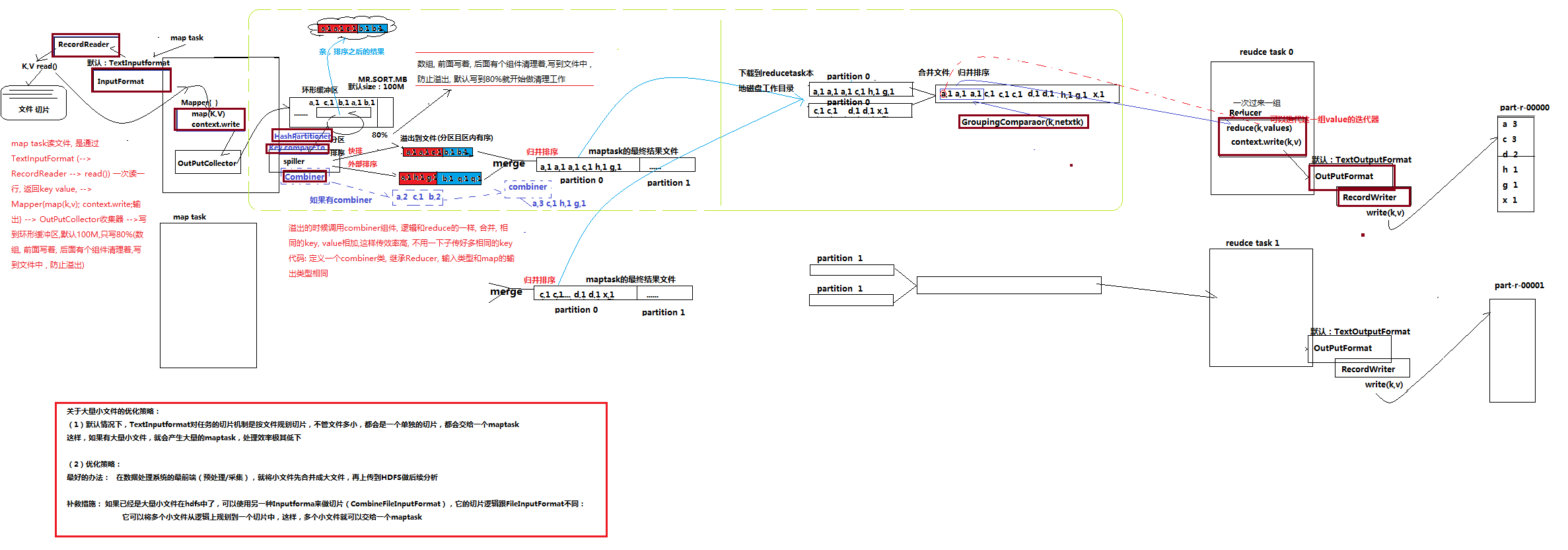
mr程序:
configuration参数设置:
conf.set(”mapreduce.framework.name","local")#是否为本地运行模式,默认为local本地模式
conf.set("fs.defaultFS","file:///") #输入输出数据的文件路径,默认为file
conf.set("fs.defaultFS","hdfs://hadoop01:9000/") #输入输出文件路径
本地运行模式文件可以用file也可以用hdfs
设置在yarn上运行程序(要想设置在集群上运行程序 一下三个参数必须设置)
conf.set(“mapreduce.framework.name”,"yarn")#设置运行模式为在集群上运行
conf.set("yarn.resourcename.hostname","hadoop01") #设置yarn的管理者resourcename在那一台机器上
conf.set("fs.defaultFS","hdfs://hadoop01:9000/") #程序在设置在yarn上运行时必须设置文件存储为hdfs
程序里面systemout的日子存在于hadoop里面的logs的userlogs里面对应job_id下的container里的syslog里面
namenode在刚启动时只包含block的数量和blockid不知道块所在datanode,要等待datanode向他汇报后才会在namenode元数据中补全文件块的位置信息,只有在namenode找到999.8%的块的位置信息才会退出安全模式正常对外提供服务。